پژوهشی دربارهٔ سیستم پیشبینی آبشاری هوشمند کیفیت سنگ آهن زینترشده مبتنی بر فناوری کلانداده
Research on cascade intelligent sinter quality prediction system based on big data technology
اصل مقاله به زبان انگلیسی را میتوانید از لینک زیر دانلود کنید:
دانلود مقالهٔ اصلی به زبان انگلیسی
در ادامه پگاه آفتاب ترجمه فارسی این مقاله را برای شما آماده کرده است:
فهرست مطالب
نویسندگان و حامیان پژوهش
نویسندگان:
ژین لی (Xin Li)، ژیائوجی لیئو (Xiaojie Liu)، ران لیئو (Ran Lui)، هونگیانگ لی (Hongyang Li) و کینگ لیو (Qing Lyu) از دانشکدهٔ متالوژی و انرژی دانشگاه علوم و فناوری شمال چین در استان هبئی، سانگ لیئو (Song Liu) از موسسه هوش مصنوعی دانشگاه تانگشان و شوجون چن (Shujun Chen) از گروه HBIS کمپانی آهن و فواد چنگده انجام شده است.
حامیان این پژوهش بنیاد ملی علوم طبیعی چین و پروژه مشترک تحقیقاتی فولاد و متالورژی آهن استان هبئی چین بودهاند.
این پژوهش ژانویهٔ ۲۰۲۴ در ژورنال Sage چاپ و منتشر شده است.
چکیده
فناوری تفجوشی (زینترینگ) در شرکتهای آهن و فولاد چین به سطح قابل قبولی رسیده است. با این حال، به دلیل مسائل جدی مربوط به منابع و محیط زیست، دستیابی به تفجوشی (زینترینگ) سبز یا سازگار با محیط زیست، هوشمندسازی تجهیزات، ارتقاء کیفیت محصولات و تسریع روند دیجیتالسازی مبتنی بر تصمیمگیری و کنترل هوشمند، همچنان مسائل کلیدی حل نشده در صنعت آهن و فولاد به شمار میروند.
این پژوهش با تکیه بر دادههای تاریخی تولید عظیم زینتر، پلتفرمی مبتنی بر کلانداده برای کل فرایند تفجوشی (زینترینگ) ایجاد میکند تا ذخیرهسازی منطقی و سازماندهی مؤثر دادههای کلان را محقق سازد.
در این راستا، سامانه پیشبینی آبشاری کیفیت زینتر (sinter quality cascade prediction system) شامل مدل پیشبینیپذیری بستر زینتر (sinter bed permeability prediction model)، مدل پیشبینی نقطه احتراق (burning through point (BTP) prediction model) و مدل پیشبینی کیفیت زینتر (sinter quality prediction model)، به همراه طراحی دقیق ساختار نرمافزاری ارائه شده است. توسعه و بهکارگیری این سامانه برای دستیابی به اهداف مهم توسعهای با آلایندگی کم، بازده بالا و کیفیت مطلوب در تولید زینتر مفید خواهد بود.
مقدمه
همانطور که اشاره شد، تکنولوژی تولید زینتر در شرکتهای آهن و فولاد چین در سالهای اخیر پیشرفت قابل توجهی داشته و تجهیزات تفجوشی (زینترینگ) به سمت اتوماسیون در مقیاس وسیع حرکت کرده است. این امر به بهبود شاخص کیفیت تولید زینتر، کاهش مصرف انرژی در فرایند، کاهش آلایندگی، تطابق با نیاز کوره بلند (large-scale blast furnace (BF)) در ابعاد بزرگ و در نهایت بهبود اثرات مثبت اجتماعی و اقتصادی تولید منجر میشود.
با این حال، دستیابی به فرایند تفجوشی (زینترینگ) سبزِ سازگار با محیطزیست، بهرهگیری از تجهیزات هوشمند، تولید محصولات باکیفیت بالا و تسریع روند تحول دیجیتال و هوشمندسازی تولید زینتر، با توجه به چالشهای جدی در حوزه منابع، انرژی و محیط زیست، همچنان به عنوان مسائل کلیدی حل نشده در صنعت فولاد امروز به شمار میروند.
فناوری کلانداده با استفاده جامع از فناوری ذخیرهسازی انبوه دادهها، پردازش آنی دادهها، انتقال پرسرعت دادهها و فناوری تحلیل دادهها، امکان جمعآوری اطلاعات دادهای، استخراج ارزش از دادهها و کشف قوانین حاکم بر دادهها را فراهم میکند. صنعت فولاد حجم عظیمی از دادهها را در اختیار دارد و توسعهی پرشتاب اینترنت اشیاء، رایانش ابری، کلانداده و سایر فناوریها، زیرساخت فنی لازم برای تحول بنگاههای فولاد به سمت هوشمندسازی و بهرهگیری از فنون اطلاعاتی را فراهم آورده است. کلانداده در صنعت فولاد به عنوان محرک اصلی نوآوری در این صنعت شناخته میشود و زمینهساز استقرار الگوی تولید پایدار با ارزش بالا و مصرف انرژی پایین در صنعت فولاد است.
بهبود سطح دیجیتالیسازی و هوشمندسازی فرایند تولید زینتر و همچنین ارتقای اثربخشی پیشبینی کیفیت تولید، به یکی از اصلیترین جهتگیریهای پژوهشی دانشمندان این حوزه تبدیل شده است.
فرایند تولید زینتر پیچیده است و تأخیر زمانی و دقت پایین در تشخیص ترکیب شیمیایی سنگ آهن زینتر، دستیابی به کنترل دقیق در تولید را با مشکل مواجه میکند. بنابراین، برای ارتقای کیفیت سنگ آهن، پیشبینی از ترکیب شیمیایی آن اهمیت ویژهای دارد.
سانگ و همکاران روشی را برای شناسایی خودکار بخشهای دارای لرزش و جایگزینی آنها بر اساس پنجرههای لغزشی جهت حل مشکل دادههای نویز در نتایج پایش تجهیزات تفجوشی (زینترینگ) پیشنهاد دادند. سپس مدل پایش آنلاین اجزا بر پایه شبکه عصبی عمیق (DNN) و مدل پیشبینی پیشرفته اجزا بر اساس شبکه عصبی مصنوعی حافظه بلندمدت و کوتاهمدت (LSTM) ساخته شد. همچنین پارامترها و ساختارهای بهینه شبکه برای هر مدل به دست آمد. نتایج آزمایشهای متعدد نشان داد که مدل پایش آنلاین مبتنی بر DNN و مدل پیشبینی پیشرفته مبتنی بر LSTM عملکرد بهتری در پیشبینی دارند. این امر بیانگر آن است که DNN برای پایش آنلاین و پیشبینی پیشرفته ترکیب زینتر مناسبتر است.
نفوذپذیری لایه مواد زینترشده، معیار مهمی برای هدایت تولید زینتر است؛ که مستقیماً بر سرعت تف جوشی (زینترینگ) عمودی و شاخص کیفیت مواد معدنی زینتر تأثیر میگذارد. آقای ژو با استفاده از شبکه عصبی و الگوریتم بهینهسازی اجتماع ذرات (particle swarm optimization algorithm)، به ترتیب یک مدل پیشبینی نفوذپذیری سری زمانی و یک مدل پیشبینی نفوذپذیری براساس پارامترهای فرایند، ایجاد کرد. همچنین برای همجوشی مؤثر این دو مدل پیشبینی، از یک کلاسیفایر فازی استفاده شد که نرخ نوسانات لحظهای نفوذپذیری زینتر (sinter permeability) را حدود ۶۰ درصد کاهش داد. لی و همکارانش با توسعه یک مدل جامع پیشبینی نفوذپذیری بر اساس تئوری بهبود یافته سیستم، به مطالعه فرایند سینترسازی سرب و روی پرداختند.
نقطه احتراق کامل (BTP) معرف سرعت سوخت عمودی روی دستگاه تفجوشی (زینترینگ) است که مستقیماً بر شاخص کیفیت تولید سنگ آهن زینتر تأثیر میگذارد. با این حال، به دلیل تأخیر و پیچیدگی فرایند تولید، نقطه BTP تنها بر اساس تجربه عملیاتی و در موقعیت دومین یا سومین محفظه هوا قابل تعیین است و هیچ ابزار مستقیمی برای اندازهگیری آن وجود ندارد. وانگ و همکارانش با استفاده از یک ماشین یادگیری حداکثری یا افراطی (ELM- Extreme learning machine) و یک الگوریتم بهبودیافته AdaBoost RS، مدلی برای پیشبینی BTP توسعه دادند و به نتایج کاربردی خوبی دست یافتند.
ایجاد ثبات در کیفیت سنگ آهن زینتر، یکی از اهداف مهم تولید زینتر است. پیشبینی اولیه پارامترهای شاخص کیفیت زینتر میتواند به کنترل مؤثر نوسانات کیفیت و ارائهی راهنمایی عملیاتی منجر شود. یی و شائو با استفاده از یک الگوریتم شبکه عصبی (BP) برای هدایت کمیت و نرخ یادگیری متغیر، یک مدل پیشبینی کیفیت زینتر را توسعه دادند و صحت و اثربخشی کاربرد مدل را تأیید کردند و و دقت پیشبینی مدل به بیش از ۸۱٫۲۵ درصد رسید.
لی و همکاران با استفاده از یک ماشین یادگیری محدود متوالی آنلاین (online sequential limit learning machine) (OS-ELM) به پیشبینی محتوای FeO (اکسید آهن (II) ) و استحکام غلتشی در هر گروه از زینتر پرداختند و نتایج تأییدشده نشان داد که مدل OS-ELM نسبت به الگوریتم شبکه عصبی (BP) متعارف از دقت بالاتری برخوردار است.
مدل پیشبینی شاخص تولید زینتر نقشی هدایتکننده در تولید واقعی ایفا میکند. این مدل میتواند به طور مؤثر به کارکنان واحد صنعتی در تثبیت تولید زینتر و ارتقای شاخص کیفیت تولید کمک کند که در پیشبرد توسعه فناوری تولید زینتر و بهبود بهرهوری اقتصادی بنگاهها از اهمیت بسزایی برخوردار است. با وجود پیشرفتهای قابل توجه در مدلهای پیشبینی فرایند سینترسازی، همچنان به دلیل پیچیدگی مکانیزم تولید سینتر، تعداد زیاد عوامل تأثیرگذار و حجم بالای دادهها، مدلهای پیشبینی فعلی با کمبودهایی مواجه هستند.
پایگاه داده مدل عمدتاً شامل دادههای آفلاین با اطلاعات محدود است، الگوریتم آن منفرد بوده و پارامترهای پیشبینی بر اساس متغیرهای محلی تعریف شدهاند که این موارد باعث محدودیت در دقت و قابلیت تعمیم مدل میشوند. فرایند تفجوشی (زینترینگ) تحت تأثیر عوامل متعددی قرار دارد و مدلهای پیشبینی موجود بیش از حد سادهسازی شدهاند و نمیتوانند به طور جامع تمامی عواملی که بر شاخص کیفیت تولید زینتر اثر میگذارند را در نظر بگیرند و همچنین قادر به تفکیک و تحلیل شاخص کیفیت (quality index) برای دستگاههای تفجوشی (زینترینگ) و خطوط تولید مختلف نیستند.
این مقاله در پاسخ به مشکلات فوق، یک سیستم پیشبینی آبشاری هوشمند (intelligent cascade prediction system) برای کیفیت سنگ آهن زینتر پیشنهاد میکند.
در گام اول، با استفاده از فناوری کلانداده، پلتفرم دادهی تفجوشی (زینترینگ) برای انجام عملیات جمعآوری، ذخیرهسازی و یکپارچهسازی دادهها ایجاد میشود.
در گام دوم، دادههای خام تولید زینتر با استفاده از مهندسی ویژگی (feature engineering) یا استخراج ویژگی یا کشف ویژگی پردازش شده تا دادههای پاک برای مدل پیشبینی به دست آید.
در مرحله سوم، مدلهای پیشبینی برای نفوذپذیری لایه زینتر، نقطه احتراق کامل (BTP) و شاخص کیفیت زینتر ایجاد میشوند. در نهایت، با بهرهگیری از فناوری کلانداده، سیستم پیشبینی آبشاری هوشمند برای کیفیت سنگ آهن زینتر به منظور پیشبینی نتایج تولید زینتر راهاندازی میشود.
ایجاد و توسعه یک سیستم پیشبینی آبشاری هوشمند برای کیفیت سنگ معدنی زینترشده
در سالهای اخیر، فناوری کلانداده در تولید چدن خام کوره بلند (BF) در چین توسعه یافته و به کار گرفته شده است و تولید چدن خام کوره بلند به تدریج به سمت سبز شدن و هوشمند شدن پیش رفته است. فرایند تفجوشی (زینترینگ) به عنوان بخش مهمی از تولید چدن خام کوره بلند، ناگزیر از گذر از تحول دیجیتال و هوشمندسازی است. با بهکارگیری فناوری مدرن کلانداده، امکان توسعهٔ یک سیستم کنترل هوشمند برای تفجوشی (زینترینگ) فراهم شده است. این سیستم پس از تکرار و بهینهسازی مداوم، سرانجام منجر به خودکارسازی فرایند تولید زینتر شده است.
سیستم پیشبینی آبشاری هوشمند کیفیت زینتر، بر پایهٔ پلتفرم دادهٔ تفجوشی (زینترینگ) بنا نهاده شده است. این سیستم با انتخاب الگوریتمهایی نظیر یادگیری ترکیبی (integrated learning) و یادگیری عمیق (deep learning)، اقدام به برقراری و توسعه سه مدل پیشبینی برای نفوذپذیری لایه زینتر، نقطه احتراق کامل (BTP) و شاخصهای کیفیت زینتر میکند. این سیستم قابلیت پیشبینی نتایج تولید را داشته و بهینهسازی لحظهای پارامترهای تولید را ممکن میسازد. بدین ترتیب، هر فرایند تفجوشی (زینترینگ) میتواند در بهترین شرایط عملیاتی صورت گیرد و پایداری و بهبود شاخصهای کیفیت زینتر حاصل شود.
جمعآوری و تلفیق دادههای تفجوشی (زینترینگ)
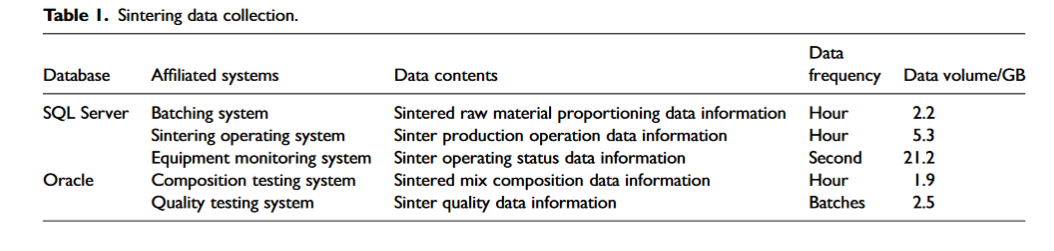
این مطالعه در سال ۲۰۲۲ اقدام به جمعآوری دادههای کل فرایند تولید یک دستگاه زینتر ۳۶۰ متری در یک کارخانه فولاد کرد. سپس دادههای استخراج شده در پایگاههای داده SQL Server و Oracle ادغام شدند. این دادهها را میتوان با ترکیب دانش تئوری تفجوشی (زینترینگ) به پنج دسته تقسیم کرد:
- پارامترهای مواد اولیه: این دادهها از سیستم بچینگ (Batching System) استخراج میشوند.
- پارامترهای ترکیب مخلوط: این دادهها از بخش تست ترکیب به دست میآیند.
- پارامترهای عملیاتی دستگاه زینتر: این دادهها از سیستم عامل عملیاتی دستگاه زینتر استخراج میشوند.
- پارامترهای وضعیت دستگاه زینتر: این دادهها از سیستم مانیتورینگ تجهیزات به دست میآیند.
- پارامترهای کیفیت سنگ آهن زینتر: این دادهها از بخش تست کیفیت استخراج میشوند.
دادههای تفجوشی (زینترینگ) در جدول ۱ نشان داده شدهاند.
جدول شماره ۱
ایجاد پلتفرم داده تفجوشی (زینترینگ)
برای جمعآوری داده از کل فرایند تولید زینتر، از فناوری کارآمد انتقال اطلاعات توزیعشده (distributed information transfer technology) استفاده میشود. این فناوری همچنین پشتیبانگیری خودکار از دادهها، بازیابی از حادثه (disaster recovery) و توزیع بار (load balancing) را برای اطمینان از صحت و امنیت دادهها فراهم میکند.
برای رفع مشکلات ناهنجاری داده، فقدان داده، توزیع با اختلاف زیاد و تناوب نامنظم در دادههای تولید زینتر، از فناوریهای پیشرفته کلانداده مانند Hadoop و Spark برای استانداردسازی فرمت داده، حذف دادههای غیرعادی، پر کردن دادههای ازدسترفته، نرمالسازی اختلاف مقیاس و همراستا کردن توالی زمانی دادهها استفاده میکنیم. همچنین دادهها را با تئوری فرایند ادغام میکنیم تا کارایی تحلیل و کاوش داده در پاسخ به این مشکلات بهبود یابد.
این پلتفرم با تکیه بر فناوری محاسبات پیشرفته و با استفاده از فناوریهای کلانداده مانند الگوریتمهای یادگیری ماشین؛ الحاق، یکپارچهسازی و عملیات دادههای چندمنبعی را برای تحقق استقرار و مدیریت کل دادههای فرایند تفجوشی (زینترینگ) تکمیل میکند.
با ترکیب تجربهٔ فرایند، دادههای حاصل از پایگاههای دادهی مختلف به طور مؤثر سازماندهی میشوند و چارچوب مدل دادهای علمی برای دادهها در سطوح، موضوعات و سناریوهای کاربردی مختلف طراحی میشود. این پلتفرم امکان تولید گزارش و دانلود پارامترهای کلیدی و همچنین تجسم نتایج تحلیل داده را فراهم میکند و بدین ترتیب، پلتفرم کلاندادهٔ تفجوشی (زینترینگ) با قابلیت ذخیرهسازی منطقی، پردازش موازی (parallel processing) و تعامل با کاربر ساخته میشود (شکل ۱).

تصویر شماره ۱ معماری پلتفرم دادههای زینترینگ (تفجوشی)
فرایند تفجوشی (زینترینگ) به عنوان یک فرایند صنعتی، دارای ویژگیهای تولید مداوم چند فرایندی، توارث قوی بین فرایندها و عوامل تأثیرگذار غیرخطی است. دادههای این فرایند با حجم بالا، وابستگی شدید، تغییر زمان و ناهمگنی شناخته میشوند.
تمامی دادههای زینتر بر اساس منبع داده، نوع داده، ساختار داده و غیره طبقهبندی میشوند. همزمان، دادهها بر اساس ویژگیهای رابطه تولید و ذخیرهسازی دادههای مختلف مرتبسازی میشوند. برای دستیابی، انتقال و کنترل بازخورد محاسبات لبهای (edge calculation) دادههای زینتر، از دستگاههای کسب اطلاعات قابل اعتماد، پلتفرم تبدیل پروتکل و سیستم پردازش لبه (edge processing system) استفاده میشود.
عمل جمعآوری دادهها، انواع مختلف داده را از منابع مختلف به صورت آنی یا فوری جمعآوری میکند و آنها را برای پردازش بیشتر به سیستم ذخیرهسازی یا سیستم دادههای میانی (intermediate data system) ارسال میکند. سیستم تفجوشی (زینترینگ) موجود دارای سیستم کنترل چند سطحی L1، L2 و L3 است و سیستم تجهیزات پیچیده است.
علاوه بر این، تفاوتهایی از حیث پروتکلهای ارتباطی، انواع سختافزار و معماریهای شبکه میان سیستمهای کنترل الکتریکی فرایندهای مختلف از تولیدکنندگان متفاوت، وجود دارد. با تعریف پروتکل تبدیل داده، مکانیزم دستیابی و انتقال داده، دسترسی دستگاه، محاسبات لبهای، دگرگونی فضایی-زمانی (spatiotemporal transformation) و هدایت پروتکل (protocol driving)، بر محدودیتهای گتویهای سختافزاری، سیستمهای داده متنوع (diverse data systems) و ساختارهای داده ناسازگار غلبه میشود. همچنین دستیابی به رابطهٔ یکپارچه و جزیره دادهٔ سیستم محقق میشود.
این پلتفرم با استفاده از مجازیسازی (virtualization)، ذخیرهسازی توزیعشده (distributed storage)، محاسبات موازی (parallel computing)، زمانبندی بار (load scheduling) و سایر فناوریها، منابع محاسباتی، منابع ذخیرهسازی، منابع شبکه و سایر خدمات زیرساخت را پوشش میدهد. این پلتفرم زیرساخت محاسبات پیشرفته، ذخیرهسازی، شبکه و سایر موارد را برای عملکردهای عملیاتی، ایجاد قابلیتها و ارائه خدمات فراهم میکند.
- هستهی مرکزی: انبارهٔ داده
انبارهٔ داده، هستهٔ اصلی این پلتفرم است. با یکپارچهسازی کلانداده، مدل ریاضی مکانیزم ذوب، تجربهٔ کارشناسان، پایگاه دانش و سایر فناوریهای چندرشتهای، تجربهٔ ارزشمند کارشناسان به شیوههای مختلف تثبیت و در فرایند تولید و عملیات واقعی اعمال میشود.
- لایهٔ بافر با تناوب بالا: این لایه دادهها را از سیستم تولید زینتر برای مدت کوتاهی (۳ روز) ذخیره میکند.
- انبار دادهٔ عملیاتی: این بخش، دادههای خام مربوط به تولید آهنسازی را برای کل چرخهٔ عمر نگه میدارد.
- مدل ابعادی یکپارچه: این مدل امکان ذخیرهٔ همهی دادههای یکپارچه و سازماندهی مجدد در فرایند آهنسازی را فراهم میکند.
- لایهٔ کاربردی: این لایه بر اساس نیازهای دادهایِ برنامههای هوشمند مستقل، امکان ذخیرهسازی شخصیسازیشدهی دادهها را فراهم میکند.
- لایهٔ شاخص: این لایه بر شاخصهای کلیدی فرایند در فرایند تولید متمرکز است و استخراج دادههای شاخص را به راحتترین شکل برای تحلیل کارآمد دادههای کلیدی ممکن میسازد.
با توجه به نیازهای هوشمند خاصِ سناریوهای مختلف در فرایند تولید زینتر، پلتفرم تحلیل تعاملی داده (interactive analysis platform) برای توسعه اپلیکیشنهای سفارشیِ هوشمندِ آهنسازی طراحی شده است تا قابلیت ماژولار بودن، استانداردسازی و تعمیمپذیری را محقق سازد. در نتیجه، این امر باعث تسریع در بازاستفاده و نوآوری دانش صنعتیِ فرایند چدن خام کوره بلند میشود. این پلتفرم، قابلیتهایی از جمله اپلیکیشنهای نوآورانهٔ صنعتی، یک جامعه از توسعهدهندگان، یک فروشگاه عرضه اپلیکیشنها، ادغام توسعه ثانویهٔ اپلیکیشن و سایر موارد را ارائه میدهد.
پیشپردازش داده
پلتفرم دادهٔ تفجوشی (زینترینگ) قادر به تأمین نیازهای جمعآوری و ذخیرهسازی داده برای کل فرایند خط تولید زینتر است. منابع و روشهای انتقال متفاوتِ دادههای تولید، منجر به بروز مشکلات کیفی در دادههای خام میشود. برای رسیدگی به کیفیت داده، این پلتفرم از طریق یکپارچهسازی، استانداردسازی و رسیدگی به دادههای پرت (outlier)، پیشپردازش دادهها را تکمیل میکند.
برای انواع مختلف دادههای خامِ زینتر که در مکانهای مختلف ذخیره شدهاند، این پلتفرم با استفاده از زمان به عنوان کلید اصلی و بر اساس ویژگیهای فرایند با تکیه بر اصول علمی فرایند متالورژی، دادههای ذخیرهشده در جداول مختلف را یکپارچه میکند. این فرایند، مدیریت دادههای کل فرایند را امکانپذیر میسازد.
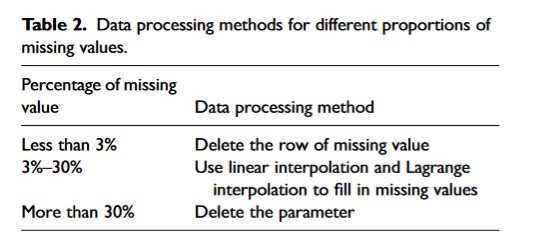
به منظور رسیدگی به مشکلات مختلف کیفیت داده، از روشهایی نظیر نمودار جعبهای (box plot)، درونیابی خطی (linear interpolation)، درونیابی لاگرانژ (Lagrange interpolation)، خوشهبندی K-means و سایر روشها استفاده میشود.
در فرایند حذف دادههای پرت، ابتدا مقادیر رکوردهای تکراری در یک زمان مشخص در مجموعه داده حذف میشوند. سپس بر اساس تجربه کارخانه تفجوشی (زینترینگ)، محدودهٔ تقریباً نرمال برخی پارامترها تعیین میشود و مقادیری که با تولید واقعی مطابقت ندارند، حذف میشوند.
در فرایند جایگزینی مقادیر مفقود، درصدهای مختلف مقادیر مفقود بر اساس رویکرد خاص ارائهشده در جدول ۲ اصلاح میشوند.
همانطور که پیشتر ذکر شد، پلتفرم دادهٔ تفجوشی (زینترینگ) قادر به تأمین نیازهای جمعآوری و ذخیرهسازی داده برای کل فرایند خط تولید زینتر است. اما منابع و روشهای انتقال متفاوتِ دادههای تولید، منجر به بروز مشکلات کیفیتی در دادههای خام میشود.
در شرایطی که حداکثر و حداقل مقادیر داده ممکن است فاقد اهمیت عملیاتی باشند، روش نرمالسازی با نمره Z (Z-score normalization) قابل اجرا است. از این روش میتوان برای شناسایی موقعیتهای غیرمعمول تولید، مانند احتمال توقف فرایند تفجوشی (زینترینگ) استفاده کرد. بنابراین، نرمالسازی با استفاده از نمره Z میتواند اثرات ناخواستهٔ مقیاسهای متفاوت را از بین ببرد.
جدول شماره ۲
فرمول نرمالسازی نمره Z در معادلات (۱) و (۲) نشان داده شده است:

فرمول شماره ۱
فرمول تبدیل نرمالسازی با نمره Z:

فرمول شماره ۲
در فرمول η میانگین کل دادهها، σ انحراف معیار دادههای کلی و x مشاهده فردی است.
توسعهٔ مدلهای پیشبینی تولید زینتر
منابع داده
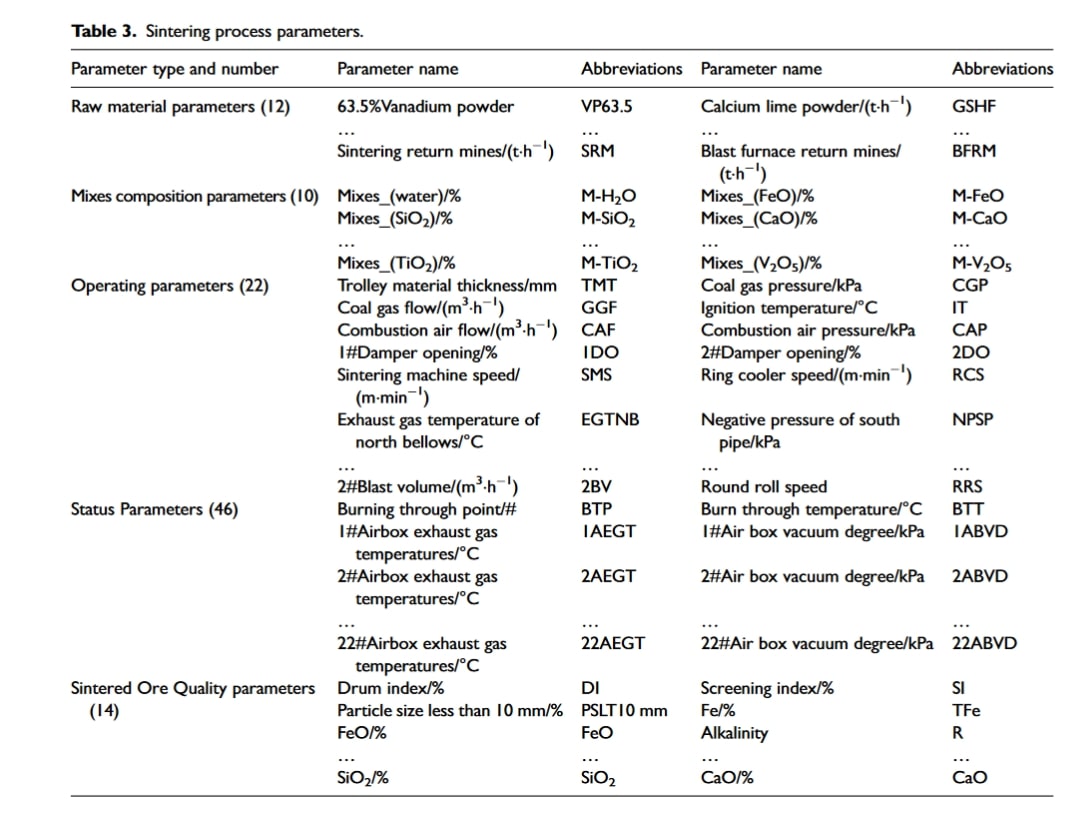
بر اساس منابع موجود در پلتفرم دادهٔ تفجوشی (زینترینگ)، در مجموع ۱۰۴ پارامتر مربوط به فرایند تولید زینتر انتخاب و بر اساس نوع داده و فرایند خاص دستهبندی شدند. برخی از نامهای پارامترها در جدول ۳ نشان داده شده است.
جدول شماره ۳
پارامترهای مواد اولیهٔ زینتر در جدول ۳، تعداد مواد اولیهٔ استفادهشده در دورههای مختلف را نشان میدهند و پارامترهای مخلوط زینتر، محتوای واقعی اجزای شیمیایی در مخلوط پس از اختلاط کامل مواد اولیه در دورههای مختلف را نشان میدهند. پارامترهای عملیاتی زینتر، فرایند تولید زینتر را که توسط پرسنل سایت کنترل میشود، نشان میدهد و پارامتر وضعیت زینتر، وضعیت عملکرد و شرایط کاری دستگاه زینتر را نشان میدهد. پارامترهای کیفیت زینتر، خواص فیزیکی و شیمیایی سنگ آهن زینتر را نشان میدهند.
مهندسی ویژگی
بر اساس دادههای پیشپردازششده (data pre-processed) در بخش قبلی، مهندسی ویژگی مدل پیشبینی تولید زینتر با استفاده از روشهای مختلف غربالگری پارامترهای ویژگی مدل پیشبینی محقق میشود.
برای حذف ویژگیهای اضافی در بین تمام پارامترهای زینتر، ابتدا با استفاده از تحلیل همبستگی پیرسون (Pearson correlation analysis) و تحلیل ضریب اطلاعات متقابل حداکثر (Maximum Mutual Information Coefficient, MIC) همهٔ ویژگیها مورد بررسی قرار میگیرند. ضریب همبستگی پیرسون رویکردی کلاسیک برای انتخاب ویژگی و یک شاخص آماری برای مطالعهٔ درجهٔ همبستگی بین متغیرها است. تعریف این ضریب در معادلهٔ (۳) ارائه شده است.
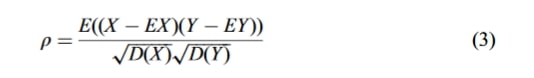
فرمول شماره ۳
در این فرمول ρ ضریب همبستگی بین متغیرها است. X متغیرهای مشخصه است. Y متغیر هدف است. D واریانس D √ است. انحراف معیار است. E مقدار میانگین است.
فرمول محاسبه تحلیل ضریب اطلاعات متقابل حداکثر یا MIC به شرح زیر است.
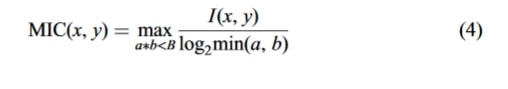
فرمول شماره ۴
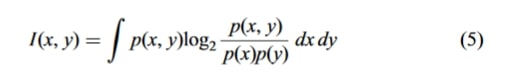
فرمول شماره ۵
در این فرمول، a و b تعداد شبکههای تقسیمشده بر اساس x و y هستند که اساساً توزیع شبکهای را نشان میدهند. مجموعه B روی ۰.۶ برابر مقدار داده تنظیم شده است.
انتخاب پارامترهای ویژگی مدل پیشبینی با استفاده از روش انتخاب ویژگی مبتنی بر درخت تصمیمگیری تقویت گرادیان (Gradient Boosting Decision Tree, GBDT) انجام میشود. بدین معنا که در فرایند ایجاد و هرس کردن یادگیری درخت تصمیم (CART)، از شاخص جینی (Gini index) درخت برای انتخاب ویژگیای که بیشترین سهم را در متغیر هدف دارد، استفاده میشود. از دیدگاه کلان، ارزش سهم ویژگی K با محاسبهی میانگین ارزش (J^2_k) ارزش سهم K در درختهای M تعیین میشود:
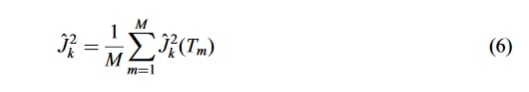
فرمول شماره ۶
از دیدگاه جزئی، ارزش سهم (J^2_k(T)) در یک درخت با حاصلضرب تابع افت گره (i^2_t) تعداد L – 1 گره غیربرگ و ویژگی وابستگی گره (v_t) نمایش داده میشود:
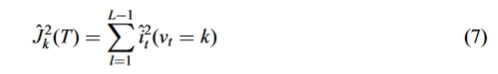
فرمول شماره ۷
شاخص جینی به عنوان یک روش اساسی برای انتخاب ویژگی، معیاری از نابرابری است. هرچه دستههای خاص در جمعیت شلوغتر باشند، شاخص بالاتر و اهمیت آنها کمتر است. به طور کلی، ویژگی با کمترین شاخص جینی در مجموعه ویژگیهای کاندید (D) به عنوان ویژگی بهینه در نظر گرفته میشود. شاخص جینی K به صورت زیر محاسبه میشود:
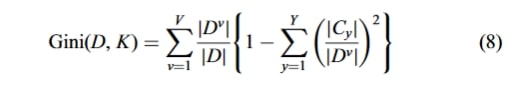
فرمول شماره ۸
در این فرمول، V تعداد تقسیمهای D، Y تعداد ویژگیها و Cy زیرمجموعهٔ ویژگی است.
روش خاص این است که از ماژول Gradient Boosting Regulator در کتابخانه Scikit-Learn استفاده شود و مدل را در یک نمونه select from model فشردهسازی کرد و به تدریج ارزشمندترین ویژگیها را برای پیشبینی مدل در نمونه انتخاب کرد.
مدل پیشبینی
سه مدل برای پیشبینی تولید زینتر به کار گرفته میشود:
۱. الگوریتم شبکهی عصبی عمیق (DNN)
شبکههای عصبی عمیق (DNN) از طریق یادگیری شبکهای مجموعهای از توابع را به دست میآورند و سپس این توابع را به صورت غیرخطی ترکیب کرده و آنها را در شبکههای عصبی با توابع پیچیدهتر نگاشت میکنند. ایدهٔ اصلی این است که با ترکیب ویژگیهای سطح پایین برای ایجاد ویژگیهای سطح بالا، فرم توزیع ویژگیهای داده را کشف کنیم. DNN نیازهای عملکردی را برای مدلسازی سیستمهای غیرخطی برآورده میکند و میتواند به طور ماهرانه با سیستمهای غیرخطی که بیان ریاضی آنها دشوار است، مطابقت کند.
فرایند ترین DNN به شرح زیر است:
ابتدا بر اساس ماتریس ورودی X و ماتریس خروجی Y، تعداد کل لایههای l و تعداد گرههای pl یعنی (l = 2, 3, …, L)، واقع در هر لایه از DNN را تعیین کنید. ماتریس وزن Wl و بردار آفست bl را بین هر یک از لایههای پنهان و لایه خروجی راهاندازی کنید و نرخ یادگیری η، آستانه تکرار ε و تابع برانگیختگی نورون را مشخص کنید. سپس، از تعدادی ماتریس ضریب وزن Wl، بردارهای سوگیری bl برای انجام مجموعهای از عملیات خطی و فعالسازی با بردار مقدار ورودی X استفاده میشود. محاسبه از لایه ورودی شروع شده و به صورت لایه به لایه به عقب برمیگردد تا به لایه خروجی برسد. در نهایت، خروجی به عنوان مقدار پیشبینیشده به دست میآید.
۲. درخت تصمیمگیری تقویت گرادیان (Gradient Boosting Decision Tree, GBDT)
الگوریتم GBDT یک مدل یادگیری ترکیبی است که از روش تقویت (boosting) استفاده میکند. مفهوم اصلی این است که مدل به طور مداوم با برازش باقیماندهها (residuals) بهبود یابد. با هر تکرار، خروجی یادگیرنده با خروجی مدل قبلی ترکیب میشود که به تدریج به هدف نزدیک میشود. این الگوریتم چندین مزیت را ارائه میدهد، از جمله:
- انعطافپذیری در مدیریت انواع مختلف دادهها
- دقت پیشبینی بالاتر
- استحکام در برابر دادههای پرت (outlier)
توضیح کلی فرایند ترین الگوریتم یادگیری GBDT به شرح زیر است:
این الگوریتم چندین تکرار را پشت سر میگذارد و در هر دور یک کلاسیفایر ضعیف ایجاد میکند. قبل از هر تکرار، مشتقات مرتبهٔ اول gi و مشتقات مرتبهٔ دوم hi تابع هزینه (Loss function) را در هر ترین محاسبه کنید. یک درخت تصمیمگیری جدید با استراتژی حریصانه ایجاد کنید و مقدار پیشبینی مربوط به هر گرهٔ نهایی را محاسبه کنید. در درخت تصمیمگیری جدید ft (x) به yt i = ˆy t−۱ i + εf t (x i) اضافه میشود، که در آن ε نرخ یادگیری نامیده میشود. مدل نهایی که باید ترین شود از مدل جمعی به دست میآید. در نهایت، پیشبینیهای مدل استخراج میشوند.
۳. مدل رگرسیون AdaBoost
رگرسیون AdaBoost یکی از بهترین الگوریتمهای تقویت است که کلاسیفایرهای مختلف (کلاسیفایرهای ضعیف) را برای مجموعه آموزشی مشابه ترین میکند و سپس این کلاسیفایرهای ضعیف را برای تشکیل یک کلاسیفایر نهایی قویتر (کلاسیفایرهای قوی) تلفیق میکند. AdaBoost از مزایای زیر برخوردار است:
- نرخ تشخیص بالا
- نرخ خطای تعمیمپذیری پایین
- عدم نیاز به تنظیم پارامتر
- مقاوم در برابر بیشآمادگی (over-adaptation)
روند الگوریتم AdaBoost به شرح زیر است:
- مقداردهی اولیهی وزنهای هر نمونه
- ترین یک کلاسیفایر ضعیف برای هر ویژگی، محاسبهٔ نرخ خطای کلاسیفایر ضعیف مربوط به تمام ویژگیها، انتخاب بهترین کلاسیفایر ضعیف و تنظیم وزنها
- از طریق چندین دور آموزش مداوم، کلاسیفایرهای ضعیف بهینهٔ چندگانه به دست آمده و در یک کلاسیفایر قوی ترکیب میشوند و با تنظیم وزنها کلاسیفایرهای جدید ایجاد میشوند تا زمانی که نرخ خطای ترین به صفر یا به مقدار مشخصی برسد.
- خروجی نتایج پیشبینی
نتایج و تحلیل پیشبینی مدل
با توجه به ماهیت پیوسته و بدون توقف تولید زینتر، استفاده از روش تقسیم تصادفی داده امکانپذیر نیست. بنابراین، برای اطمینان از ثبت ویژگیهای چرخه پارامتری، مجموعه دادهٔ پیشپردازششده (ژانویه تا دسامبر ۲۰۲۲) باید با استفاده از روش «باقیمانده» (leave-out method) به ترتیب زمانی به مجموعههای آموزشی و آزمایشی با نسبت ۹:۱ تقسیم شود. برای ارزیابی بازده پیشبینی مدل از ضرایب میانگین خطای مطلق (Mean Absolute Error – MAE)، میانگین توان دوم خطاها (mean squared error – MSE) و ضریب تعیین R2 (R-squared correlation) استفاده شد.
تولید گندلهٔ آهن باکیفیت برای ذوب در کوره بلند (BF) به فرایند زینتر وابسته است و پایداری آن عمدتاً به نفوذپذیری لایهی زینتر بستگی دارد. برای اطمینان از نفوذپذیری هوای کافی در طول فرایند زینتر، ایجاد یک مدل پیشبینی برای نفوذپذیری هوای لایهٔ زینتر که قابل پایش و پیشبینی باشد، ضروری است.
پس از استفاده از روش انتخاب ویژگی برای غربال کردن پارامترهای ویژگی مهم، در مجموع ۱۸ پارامتر ویژگی مهم مانند IT، M-CaO، CGP، NPSP، M-FeO، EGTNB، CAP، M-H2O، ۱ABVD، ۲BV، M-V2O5، ۱BV، RRS، SMS، CAF، ۲DO، ۱AEGT و EGTSB برای مدل پیشبینی نفوذپذیری لایهی مواد زینتر شده انتخاب شدند. برای توسعهٔ مدل پیشبینی نفوذپذیری لایه از شبکهی عصبی عمیق (DNN) استفاده شد. سپس کارایی مدل با استفاده از یک مدل جنگل تصادفی (Random Forest) و یک مدل ماشین بردار پشتیبان (Support Vector Machine) مورد آنالیز تطبیقی قرار گرفت. نتایج پیشبینی مدل در جدول ۴ و شکل ۲ نشان داده شده است.
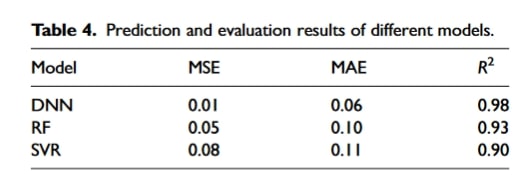
جدول شماره ۴
با مقایسه با سایر مدلها، مقادیر پیشبینیشدهٔ نفوذپذیری با استفاده از شبکهی عصبی عمیق (DNN) مطابقت خوبی با مقادیر واقعی دارند. معیارهای ارزیابی برای مدل، از جمله R2 برابر با ۰.۹۸، MSE برابر با ۰.۰۱ و MAE برابر با ۰.۰۶، نشاندهندهٔ عملکرد عالی پیشبینی و مناسب برای پیشبینی نفوذپذیری در لایهٔ مواد خام زینتر شده هستند. این مدل را میتوان در عمل برای کمک به اپراتور در ارزیابی دقیق نفوذپذیری لایهٔ مواد به کار برد. این امر امکان کنترل و تنظیم پیشرفتهٔ پارامترها را فراهم میکند و از بروز حوادث و در نتیجه کاهش تولید جلوگیری میکند.

تصویر شماره ۲ مقایسه مقادیر پیشبینیشده و واقعی DNN
موقعیت دمای احتراق کامل (BTP) مستقیماً بر کیفیت تولید زینتر تأثیر میگذارد. با این حال، به دلیل پیچیدگی و ماهیت دینامیکی و متغیر با زمانِ فرایندِ تولید زینتر، دقت پایش نقطهٔ پایان تفجوشی (زینترینگ) پایین و تأخیر زمانی قابل توجهی وجود دارد؛ که تعیین وضعیت BTP را دشوار میکند. بنابراین، برای دستیابی به یک پیشبینی دقیق، اصول و ویژگیهای ذاتی مؤثر بر تغییر BTP از دادههای تاریخچهی زینتر استخراج شده و برای ایجاد مدل پیشبینی BTP به کار گرفته میشود.
در مجموع ۱۸ پارامتر ویژگی مهم مانند IT، M-CaO، CGP، NPSP، M-FeO، DI، VP63.5، RCS، M-V2O5، M-H2O، CAP، ۲۱AEGT، ۱AEGST، SMS، ۱ABVD، ۲۲ABVD، ۲DO و EGTNB برای مدل پیشبینی BTP انتخاب شدند. برای ساخت مدل پیشبینی BTP از الگوریتم GBDT استفاده شد، در حالی که مدلهای جنگل تصادفی (Random Forest) و شبکهٔ عصبی برای اعتبارسنجی مقایسهای انتخاب شدند. نتایج پیشبینی الگوریتم GBDT با سایر مدلها در جدول ۵ و مقایسهٔ مقادیر پیشبینیشده و واقعی BTP با GBDT در شکل ۳ نشان داده شده است.

تصویر شماره ۳ مقایسه مقادیر پیشبینیشده و واقعی BTP
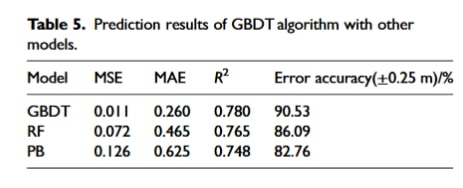
جدول شماره ۵
همانطور که جدول ۵ و شکل ۳ نشان میدهند، مدل پیشبینی نقطه احتراق (BTP) با استفاده از الگوریتم GBDT با دقت زیاد مقادیر را مطابق با نتایج واقعی پیشبینی میکند و به نتایج پیشبینی مطلوبی دست مییابد. شاخصهای ارزیابی برای این مدل عبارتند از: R2 برابر با ۰.۷۸۰، MSE برابر با ۰.۱۱ و MAE برابر با ۰.۲۶. همچنین، دقت مدل در پیشبینی خطاهای کمتر از ۰.۲۵ متر به ۹۰.۵۳ درصد میرسد. این مدل در سایتی واقعی اجرا شده است و تأثیر مثبتی بر توانایی اپراتور در تعیین وضعیت BTP داشته است.
آزمایش کیفیت سنگ آهن زینترشده با تأخیر زمانی همراه است. برای غلبه بر این مشکل، یک مدل پیشبینی آبشاری برای «شاخص کیفیت مواد معدنی زینتر شده» (sintered mineral quality index) بر اساس دادههای کل فرایند تولید زینتر ساخته شده است. این مدل با ترکیب خروجی دو مدل دیگر که پیشتر توضیح داده شد (مدل پیشبینی نفوذپذیری لایه مواد زینترشده و مدل پیشبینی وضعیت نهایی یکپارچهٔ زینتر) و با تکیه بر تحلیل مکانیسم اثرگذاری عوامل مختلف، پارامترهای کلیدی مؤثر بر کیفیت مواد معدنی زینترشده را تعیین میکند.
این مدل کل فرایند را در بر میگیرد، از اختلاط جامع مواد اولیه گرفته تا فرایند تفجوشی (زینترینگ) و در نهایت محصولات نهایی. با پیشبینی دقیق پارامترهایی مانند شاخص درام سنگ آهن زینترشده (sintered ore drum index) و شاخص الک (sieve index)، این مدل به اپراتور خط تولید این امکان را میدهد تا روند تغییرات شاخص کیفیت مواد معدنی زینترشده را به موقع کنترل کند.
پس از غربال کردن پارامترهای کلیدی، در مجموع ۱۲ پارامتر برای مدل پیشبینی شاخص درام سنگ آهن زینتر شده انتخاب شدند. این پارامترها عبارتند از:
- نقطه احتراق (BTP)
- اکسید آهن (II) (M-FeO)
- کلسیم آلومینات فریت (CAF)
- رطوبت (M-H2O)
- ظرفیت جذب آب (CAP)
- میانگین دمای گاز خروجی ۲۱ متر بعد از بخش خشککن (۲۱AEGT)
- سیلیس، منیزیم، اکسیدهای قلیایی (SMS)
- پنتا اکسید وانادیم (M-V2O5)
- میانگین دمای گاز خروجی (EGT)
- میانگین درصد اکسیژن (DO)
- میانگین درصد بخار آب (BV)
- نفوذپذیری هوای لایه مواد
برای مدل پیشبینی شاخص الک، در مجموع ۱۸ پارامتر انتخاب شدند که عبارتند از:
- نقطه احتراق (BTP)
- نسبت بازگشت دانههای ریز (RRS)
- سیلیس، منیزیم، اکسیدهای قلیایی (SMS)
- رطوبت (M-H2O)
- میانگین درصد بخار آب خروجی ۹ متر بعد از بخش خشککن (۹ABVD)
- میانگین دمای گاز خروجی ۲۱ متر بعد از بخش خشککن (۲۱AEGT)
- میانگین دمای گاز خروجی ۱ متر بعد از بخش خشککن (۱AEGT)
- میانگین درصد بخار آب خروجی ۱ متر بعد از بخش خشککن (۱ABVD)
- اکسید آهن (II) (M-FeO)
- ظرفیت جذب آب (CAP)
- میانگین درصد بخار آب خروجی ۳ متر بعد از بخش خشککن (۳ABVD)
- کلسیم آلومینات فریت (CAF)
- پنتا اکسید وانادیم (M-V2O5)
- میانگین دمای گاز خروجی در ۲ متر بعد از بخش خشککن (۲AEGT)
- میانگین دمای گاز خروجی (EGT)
- میانگین درصد اکسیژن (DO)
- میانگین درصد بخار آب (BV)
- نفوذپذیری هوای لایه مواد
برای پیشبینی شاخص درام و شاخص الک به ترتیب از مدل رگرسیون AdaBoost و برای مقایسه کارایی مدل از مدلهای GBDT و RF استفاده شد. نتایج پیشبینی مدل در جدول ۶، شکل ۴ و شکل ۵ نشان داده شده است.
جدول شماره ۶

شکل شماره ۴ نتایج شبیهسازیشدهٔ شاخص درام سینتر مدل پیشبینی

شکل شماره ۵ نتایج شبیهسازیشدهٔ شاخص غربالگری سینتر مدل پیشبینی
همانطور که از جدول ۶ و شکل ۴ و ۵ مشخص است، شاخصهای ارزیابی برای شاخص درام و شاخص الک با استفاده از مدل AdaBoost نسبت به سایر مدلها بالاتر است. R2 به ترتیب ۰.۸۹ و ۰.۸۷۲ میباشد. MSE نیز به ترتیب ۰.۰۰۹ و ۰.۰۷۳ است. MAE نیز به ترتیب ۰.۵۶۶ و ۰.۳۵۴ است.
قابل توجه این که که خطاهای پیشبینی مدل AdaBoost برای شاخص درام سنگ آهن زینترشده بیش از ۸۵ درصد است؛ که این میزان با نیازمندیهای واقعی تولید در فرایند تفجوشی (زینترینگ) مطابقت دارد. با اعمال این مدل در کارخانهی واقعی، اپراتورها میتوانند به موقع روند تغییرات شاخصهای کیفیت مواد معدنی زینتر شده را درک کنند که این امر نقش مثبتی در بهبود کیفیت سنگ آهن زینتر شده ایفا میکند.
توسعه سیستم هوشمند پیشبینی کیفیت زینتر
ساختار سیستم
با ایجاد یک مدل پیشبینی نفوذپذیری لایهٔ مواد زینترشده، یک مدل پیشبینی وضعیت نهایی زینتر و یک مدل پیشبینی کیفیت مواد معدنی زینتر شده، یک سیستم هوشمند پیشبینی کیفیت مواد معدنی زینتر شده بهصورت آبشاری بهطور مشترک ایجاد میشود تا امکان پیشبینی نتایج تولید، بهینهسازی پارامترهای تولید و دستیابی به هدف تثبیت و بهبود شاخص کیفیت مواد معدنی زینتر فراهم شود.
سیستم هوشمند پیشبینی کیفیت زینتر به صورت آبشاری از لحاظ ساختار نرمافزاری به سه لایه تقسیم میشود: لایه ارتباط داده، لایه پیشبینی پارامتر و لایه کنترل تصمیمگیری (شکل ۶).
۱. لایه ارتباط داده
این لایه مسئول برقراری ارتباط با سامانه انبار داده مربوط به فرایند زینتر (Sinter Data Warehouse) است.
۲. لایه پیشبینی پارامتر
در این لایه، ماژولهای پیشبینی پارامترهای کلیدی فرایند زینتر قرار دارند. این ماژولها عبارتند از:
- ماژول پیشبینی نفوذپذیری لایه مواد زینتر شده
- ماژول پیشبینی نقطه احتراق (BTP)
۳. لایه کنترل تصمیمگیری
در این لایه، ماژول پیشبینی آبشاری کیفیت مواد معدنی زینتر شده قرار دارد. این ماژول از خروجی ماژولهای موجود در لایه پیشبینی پارامتر برای پیشبینی نهایی کیفیت مواد معدنی زینتر شده استفاده میکند.
شکل ۶ ساختار کلی این سیستم را نشان میدهد.

شکل شماره ۶ ساختار نرمافزار سیستم پیشبینی آبشاری هوشمند زینتر
ماژول انبار داده زینترینگ عمدتاً ذخیره و بازیابی پارامترهای مربوطه را در سیستم پیشبینی و بهینهسازی متوجه میشود و دادههای مورد نیاز برای عملیات مدل را از پایگاه داده از طریق دستورات SQL میخواند.
در محیطهای عملیاتی، سیستمهای پیشبینی اغلب به عنوان اجزای مستقل ادغام میشوند. برای دستیابی به بهرهوری مطلوب و به حداقل رساندن زمان پاسخگویی سرویس پیشبینی در فواصل با تراکم کاری بالا، استفاده از سرورهای چند هستهای ضروری است.
در این سیستم، الگوریتمهای پیشبینی با فریمورک Flask Web پایتون ادغام شدهاند. این کار باعث میشود تا سیستم بتواند از طریق فراخوانیهای http، سرویسهای پیشبینی را به سایر سیستمها ارائه دهد. به دلیل مسائل مربوط به هزینه، استقرار این سیستم پیشبینی در چندین ماشین با استفاده از Kubernetes (k8s) باعث استفادهٔ کامل از منابع سرور میشود.
برای مدیریت مقیاسپذیری سرویسها از HPA (horizontal pod autoscaling) استفاده میشود. برای بهبود مدیریت خوشههای k8s از ابزارهای KubeSphere بهره گرفته میشود. پلتفرم KubeSphere یک رابط کاربری گرافیکی و یک رابط خط فرمان در اختیار کاربران قرار میدهد که به منظور استقرار، مدیریت و مانیتورینگ آسانِ اپلیکیشنها طراحی شده است. کاربران به راحتی میتوانند با استفاده از KubeSphere به طراحی، بهروزرسانی و توسعهی اپلیکیشنها بپردازند.
کارآیی سیستم
ماژول پیشبینی نفوذپذیری لایهٔ مواد زینترشده بر اساس دادههای لحظهای پارامترهای مواد اولیه، پارامترهای تجهیزات و پارامترهای فرایند کار میکند. این دادهها به طور غیرمستقیم پارامترهایی را که اندازهگیری لحظهای آنها دشوار است، از طریق پارامترهای عملیاتی و وضعیت فرایند منعکس میکنند. این ماژول میتواند با کنترل تولید فرایند زینتر و بهینهسازی عملکرد اختلاط، به موقع اقدامات لازم را انجام دهد. همچنین، این ماژول برای تنظیم و بهینهسازی نفوذپذیری لایهٔ مواد، رطوبت، اندازهٔ ذرات و تخصیص کربن مخلوط را به صورت لحظهای پایش و هشدار میدهد.
همانطور که در شکل ۷ نشان داده شده است، ماژول پیشبینی نفوذپذیری لایهٔ مواد زینترشده، روندهای نمایی نفوذپذیری لایهٔ مخلوط برای نسبتهای مختلف مواد اولیه و همچنین پایش لحظهای رطوبت، اندازهی ذرات و تخصیص کربن مخلوط را به نمایش میگذارد.
شکل شماره ۷ مدل پیشبینی نفوذپیری لایهٔ مواد خام زینترینگ
ماژول پیشبینی نقطه احتراق (BTP) موقعیت لحظهای BTP را بر اساس مقدار اندازهگیری دمای گاز خروجی از باکس انفجار و طول بوژی در زمان حقیقی (Real Time) محاسبه میکند. مدل پیشبینی BTP با دریافت پارامترهای آنلاین از دستگاه سینتر، میتواند تغییر موقعیت BTP را پس از ۱۵ دقیقه پیشبینی کند. نتایج لحظهای موقعیت BTP همراه با مقدار پیشبینی شده به اپراتور خط تولید در تحلیل و تنظیم نوسانات موقعیت BTP کمک میکند.
همانطور که در شکل ۸ نشان داده شده، ماژول پیشبینی موقعیت BTP نمودارهای دادهی لحظهای و پیشبینیشدهٔ موقعیت BTP و دمای انتهایی را به همراه هیستوگرام دادهٔ لحظهای دمای گاز خروجی از باکس انفجار نمایش میدهد. این نمایش بصری ارزیابی جامعی از وضعیت BTP ارائه میدهد و معیارهای پارامتر برای حالت گذشته، حالت فعلی و حالت هدف را به کاربر ارائه میکند.
شکل شماره ۸ مدل پیشبینی BTP
ماژول پیشبینی آبشاری کیفیت زینتر، پایش لحظهای و پیشبینی پیشرفتهی شاخصهای کیفیت مواد معدنی زینتر را ارائه میدهد. مدل پیشبینی با استفاده از مشخصات مخلوط، پارامترهای عملیاتی فرایند زینتر و پارامترهای وضعیت به عنوان ورودی، شاخص کیفیت سنگ آهن زینتر شده را در انتهای دستگاه زینتر به صورت لحظهای محاسبه میکند. این ماژول به اپراتور سایت کمک میکند تا از بروز غیرعادی بودن در خواص مواد معدنی زینتر، از پیش مطلع شود.
همانطور که در شکل ۹ نشان داده شده است، ماژول هوشمند پیشبینی آبشاری کیفیت زینتر، نمودارهای لحظهای پارامترهای پیشبینیشدهٔ شاخص درام و شاخص الک را نمایش میدهد که نشانگر کیفیت سنگ آهن زینتر شده هستند.

شکل شماره ۹ مدل پیشبینی سنگآهن زینتر و شاخص کیفیت
از زمان پیادهسازی سیستم پیشبینی و بهینهسازی پارامترهای فرایند تفجوشی (زینترینگ)، بهبودهای قابل توجهی در بهینهسازی مخلوط، کنترل ترکیب شیمیایی و شاخصهای کیفیت مواد معدنی زینتر مشاهده شده است. پس از ۳ ماه استفاده از این سیستم، به طور میانگین، میزان تثبیت آهن کل (TFe) در مواد معدنی زینتر شده تقریباً ۱.۰۳ درصد، میزان تثبیت نسبت CaO/SiO2 حدود ۳.۱ درصد و شاخص درام و شاخص الک مواد معدنی زینتر به ترتیب حدود ۰.۱۸ درصد و ۴.۲ درصد افزایش یافته است. همچنین، مصرف سوخت جامد برای تولید مواد معدنی زینتر به ۵ کیلوگرم به ازای هر تن کاهش یافته است.
با اعمال سیستم هوشمند پیشبینی آبشاری کیفیت زینتر در محل کارخانه، اپراتورها میتوانند شاخصهای کلیدی مورد نظر در تولید زینتر را به صورت لحظهای مشاهده کنند. این امر، پشتیبانی دادهای مؤثرتر و مطلوبتری را برای اپراتورهای سایت فراهم میآورد. با استفاده از این سیستم، میتوان شاخصهای ترکیبی مواد معدنی زینتر شده را پایدارتر کرد. این موضوع، مبنای تحقیقات نظری و تضمینی مهم برای دستیابی به اهداف مهم صرفهجویی در مصرف انرژی، افزایش تولید و ارتقای کیفیت در فرایند تولید زینتر به شمار میرود.
نتیجهگیری
۱. در این پژوهش، روشی نوآورانه برای ایجاد یک «سامانه هوشمند پیشبینی آبشاری کیفیت سنگ آهن زینترشده» پیشنهاد میشود. این روش با ایجاد یک پلتفرم کلاندادههای مربوط به فرایند تفجوشی یا زینترینگ که انبارهٔ بینقصی از دادهها را فراهم میکند، زیربنای توسعه این سامانه را بنا میسازد. سپس با تحلیل مکانیزم فرایند، مدلهایی برای نفوذپذیری سنگ آهن و مدل نقطه احتراق BTP ساخته میشود تا عوامل کلیدی تأثیرگذار بر شاخص کیفیت سنگ آهن شناسایی شوند. در نهایت، با ترکیبِ نتایج حاصل از تحلیل دادهها و این دو مدل فرعی، یک مدل پیشبینی آبشاری برای شاخص کیفیت سنگ آهن سینترشده ایجاد میگردد. این سیستم با ارائهٔ دادهها و پیشبینیهای مؤثر به کارکنان خط تولید (اپراتورهای میدانی)، آنها را قادر میسازد تا با تنظیمات مناسب در فرایند تفجوشی یا زینترینگ، به ثبات و بهینهسازی کیفیت نهایی محصول دست یابند. به طور کلی، این روش با بهرهگیری از کلان داده و تکنیکهای مدلسازی، پایداری و پیشبینیپذیریِ تولید سنگ آهن سینتر شده با کیفیت بالا را هدف قرار میدهد.
۲. برای پیادهسازی سیستم پیشبینی آبشاری هوشمند کیفیت سنگ آهن، طراحی دقیق ساختار نرمافزاری آن ارائه شده است. این سیستم با قابلیت تثبیت شاخص ترکیب، به طور موثری کیفیت و شاخص خروجی تولیدِ سنگ آهن را بهبود میبخشد و زمینهٔ دستیابی به اهداف مهم توسعهٔ پایدار، شامل تولید با میزان آلایندگی کم، بازدهی بالا و کیفیت بالای سنگ آهن را فراهم میکند. توسعهٔ این سیستم، نمایانگر سرعت بالای پیشرفتِ دیجیتالیسازی و هوشمندسازی در صنعت فولاد است و بستر نظری و عملی محکمی را برای تحقق «تولید سبز یا دوستدار محیطزیست» در این صنعت فراهم میسازد.
منابع
۱٫ Tang XJ. The course, current situation and some opinions of the large-scale sintering machine. In: Zhangjiajie: Proceedings of the 2011 National Sintering Pellet Technology Exchange Annual Conference, 2011.
۲٫ Zhou WT, Hu JG and Guo YL. Research progress of new technologies for increasing sinter machine productivity. Sinter Pelletizing 2016; 01: 1–۶٫
۳٫ Zhou JC, Zhang CX, Li XP, et al. Reasonable recycling methods of waste heat at steel plants based on energy level analysis. Iron Steel 2013; 48: 80–۸۵٫
۴٫ Wang WX. Review on ironmaking technology of key steel enterprises in 2010. Zhangjiajie: Proceedings of the 2011 National Ironmaking Low-Carbon Technology Symposium, 2011.
۵٫ Liu XJ, Li X, Liu EH, et al. Research status and prospect of big data technology in blast furnace ironmaking production. Compr Util Miner 2021; 4: 91–۹۶٫
۶٫ Long HM. Mathematical model of metallurgical process and application of artificial intelligence. Beijing: Metallurgical Industry Press, 2010.
۷٫ Fan XH, Feng J, Chen XL, et al. Prediction model and control-guidance expert system of sinter chemical compos- ition. Min Metall Eng 2011; 31: 77–۸۰٫ +۸۵٫
۸٫ Song L, Qing L, Xiaojie L, et al. A prediction system of burn through point based on gradient boosting decision tree and deci- sion rules. Ironmaking & Steelmaking 2020; 47(7): 828–۸۳۶٫
۹٫ Xu CH. Neural-network-based prediction of permeability. J Liuzhou Teach Coll 2010; 25: 117–۱۲۳٫
۱۰٫ Lei D, Min W, Jinhua S, et al. Synthetic permeability for lead- zinc sintering process based on the improved gray theory. Chin High Technol Lett 2009; 19: 877–۸۸۰٫
۱۱٫ Wang SH, Li HF, Zhang YJ, et al. Prediction and analysis of burning though point base on modified AdaBoost RS algo- rithm. China Metall 2019; 29: 13–۱۹٫
۱۲٫ Yi ZM and Shao HJ. A prediction model for sintering quality based on control of process parameters. Min Metall Eng 2018; 38: 92–۹۶٫
۱۳٫ Li Z, Fan X, Chen G, et al. Optimization of iron ore sintering process based on ELM model and multi-criteria evaluation. Neural Comput Appl 2017; 28: 2247–۲۲۵۳٫
